In a study of insurance availability in Chicago, the U.S. Commission on Civil Rights attempted to examine charges by several community organizations that insurance companies were redlining their neighborhoods, ie. cancelling policies or refusing to insure or renew. First the Illinois Department of Insurance provided the number of cancellations, non-renewals, new policies, and renewals of homeowners and residential fire insurance policies by ZIP code for the months of December 1977 through February 1978. The companies that provided this information account for more than 70% of the homeowners insurance policies written in the City of Chicago. The department also supplied the number of FAIR plan policies written an renewed in Chicago by zip code for the months of December 1977 through May 1978. Since most FAIR plan policyholders secure such coverage only after they have been rejected by the voluntary market, rather than as a result of a preference for that type of insurance, the distribution of FAIR plan policies is another measure of insurance availability in the voluntary market.
Secondly, the Chicago Police Department provided crime data, by beat, on all thefts for the year 1975. Most Insurance companies claim to base their underwriting activities on loss data from the preceding years, i.e. a 2-3 year lag seems reasonable for analysis purposes. the Chicago Fire Department provided similar data on fires occurring during 1975. These fire and theft data were organized by zip code.
Finally the US Bureau of the census supplied data on racial composition, income and age and value of residential units for each ZIP code in Chicago. To adjust for these differences in the populations size associated with different ZIP code areas, the theft data were expressed as incidents per 1,000 population and the fire and insurance data as incidents per 100 housing units.
The variables are
race: racial composition in percent minority
fire: fires per 100 housing units
theft: theft per 1000 population
age: percent of housing units built before 1939
volact: new homeowner policies plus renewals minus cancellations and non renewals per 100 housing units
involact: new FAIR plan policies and renewals per 100 housing units
income: median family income
The data comes from the book ``Data : a collection of problems from many fields for the student and research worker'' by D. Andrews and A. Herzberg (published by Springer). We choose the Involuntary market activity variable (the number getting FAIR plan insurance) as the response since this seems to be the best measure of those who are denied insurance by others. Note that it is not a perfect measure because some who are denied insurance may give up and others still may not try at all for that reason.
Furthermore, we do not know the race of those denied insurance. The voluntary market activity variable is not as relevant. We will focus on the relationship between race and the response although similar analyses should be done for the income variable.
Start
by reading the data in and examining it:
> chicago <-
read.table("chicago.txt")
> chicago
race fire
theft age volact involact
income
60626 10.0 6.2 29 60.4 5.3 0.0 11744
60640 22.2 9.5 44 76.5 3.1 0.1 9323
…deleted…
60645 3.1 4.9 27 46.6 10.9 0.0 13731
Rescale the income variable and omit volact
>
chicago <- data.frame(chicago[,1:4],chicago[,6],chicago[,7]/1000)
>
chicago
race fire
theft age chicago...6.
chicago...7..1000
60626 10.0 6.2 29 60.4
0.0
11.744
60640 22.2 9.5 44 76.5
0.1
9.323
…deleted…
60645 3.1 4.9 27 46.6 0.0 13.731
Fix up the variable names and summarize:
>
names(chicago) <- c("race","fire","theft","age","involact","income")
>
summary(chicago)
race
fire
theft
age
involact
income
Min. : 1.00 Min. : 2.00 Min. : 3.00 Min. : 2.00 Min. :0.0000 Min. : 5.583
1st Qu.: 3.75 1st Qu.: 5.65 1st Qu.: 22.00 1st Qu.:48.60 1st Qu.:0.0000 1st Qu.: 8.447
Median :24.50 Median :10.40 Median : 29.00 Median :65.00 Median :0.4000 Median :10.694
Mean :34.99 Mean :12.28 Mean : 32.36 Mean :60.33 Mean :0.6149 Mean :10.696
3rd Qu.:57.65 3rd Qu.:16.05 3rd Qu.: 38.00 3rd Qu.:77.30 3rd Qu.:0.9000 3rd Qu.:11.989
Max. :99.70 Max. :39.70 Max. :147.00 Max. :90.10 Max. :2.2000 Max. :21.480
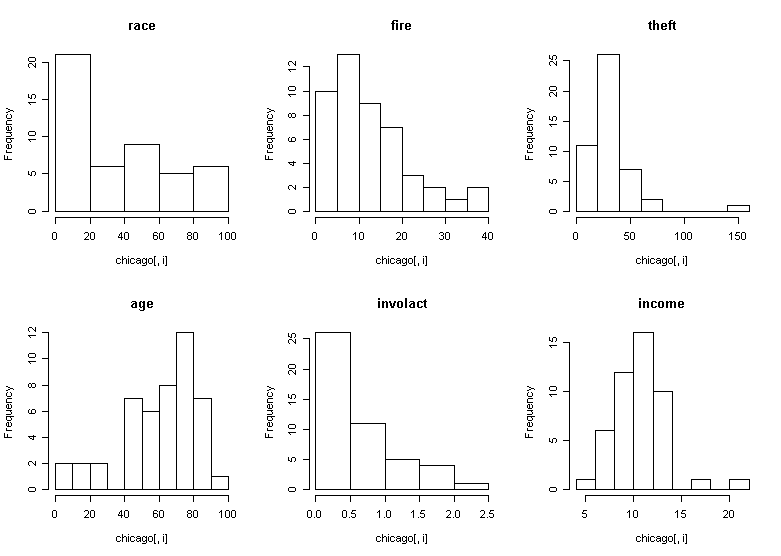
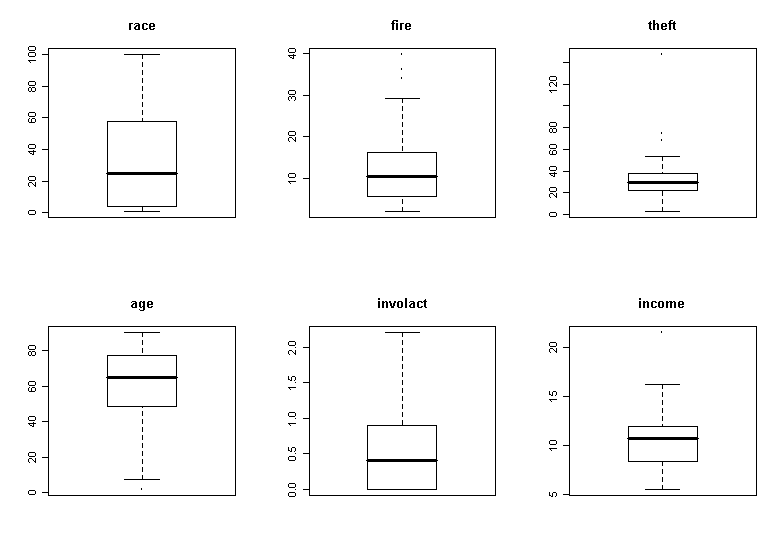
What do you notice? We see that there is a wide range in the race variable with some zip codes being almost entirely minority or non-minority. This is good for our analysis since it will reduce the variation in the regression coefficient for race, allowing us to assess this effect more accurately. If all the zip codes were homogenous, we would never be able to discover an effect from this aggregated data. We also note some skewness in the theft and income variables. The response involact has a large number of zeros. This is not good for the assumptions of the linear model but we have little choice but to proceed.
Now
make some graphical summaries:
> par(mfrow=c(2,3))
> for(i in
1:6) hist(chicago[,i],main=names(chicago)[i])
> for(i in 1:6) boxplot(chicago[,i],main=names(chicago)[i])
> pairs(chicago)
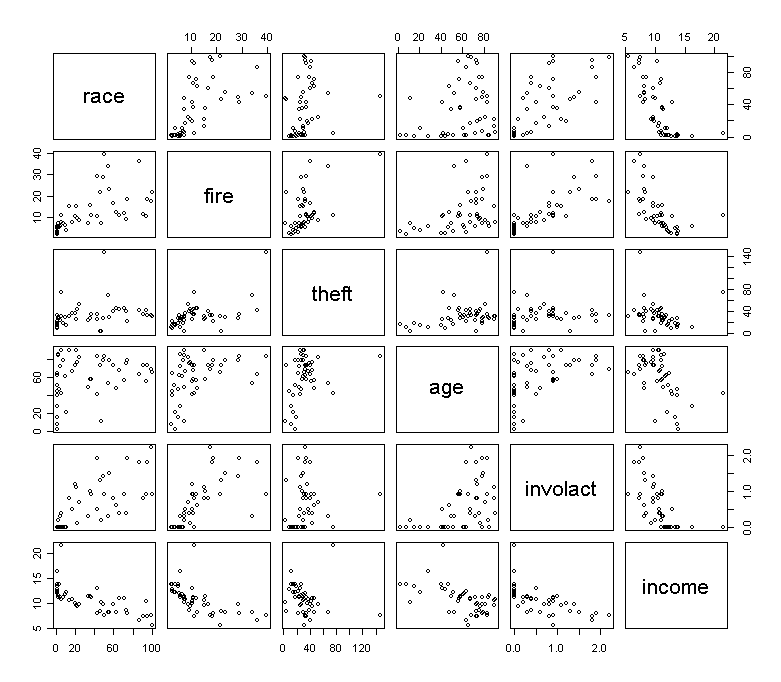
What have you observed from the plots?
Now look at the relationship between involact and race:
> summary(lm(involact ~ race,data=chicago))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.129218 0.096611 1.338 0.188
race
0.013882 0.002031 6.836 1.78e-08 ***
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1
` ' 1
Residual standard error: 0.4488
on 45 degrees of freedom
Multiple R-Squared:
0.5094, Adjusted
R-squared: 0.4985
F-statistic: 46.73 on 1 and 45 DF, p-value: 1.784e-08
We can clearly see that zip codes with high % minority are being denied insurance at higher rate than other zip codes. That is not in doubt. However, can the insurance companies claim that the discrepancy is due to greater risks in some zip-codes? For example, we see that % minority is correlated with the fire rate from the plots. The insurance companies could say that they were denying insurance in neighborhoods where they had sustained large fire-related losses and any discriminatory effect was a by-product of (presumably) legitimate business practice. What can regression analysis tell us about this claim?
The question of which variables should also be included in the regression so that their effect may be adjusted for is difficult. Statistically, we can do it, but the important question is whether it should be done at all. For example, it's known that the incomes of women is the US are generally lower than those of men. However, if one adjusted for various factors such as type of job and length of service, this gender difference is reduced or can even disappear. The controversy is not statistical but political --- should these factors be used to make the adjustment?
In this example, suppose that if the effect of adjusting for income differences was to remove the race effect? This would pose an interesting but non-statistical question. I have chosen to include the income variable here just to see what happens. I use log(income) partly because of skewness in this variable but also because income is better consider on a multiplicative rather than additive scale. In other word, $1,000 is worth a lot more to a poor person than a millionaire because $1,000 is a much greater fraction of the poor person's wealth.
Now, we start with the full model:
>
g <- lm(involact ~ race + fire + theft + age + log(income), data =
chicago)
> summary(g)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.185540 1.100255 -1.078 0.287550
race
0.009502 0.002490 3.817 0.000449 ***
fire
0.039856 0.008766 4.547 4.76e-05 ***
theft
-0.010295
0.002818 -3.653 0.000728
***
age
0.008336 0.002744 3.038 0.004134 **
log(income) 0.345762 0.400123 0.864 0.392540
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1
` ' 1
Residual standard error: 0.3345
on 41 degrees of freedom
Multiple R-Squared:
0.7517, Adjusted
R-squared: 0.7214
F-statistic: 24.83 on 5 and 41 DF, p-value: 2.009e-11
Before we start making any conclusions, we should check the model assumptions.
> par(mfrow=c(2,2))
> plot(g)
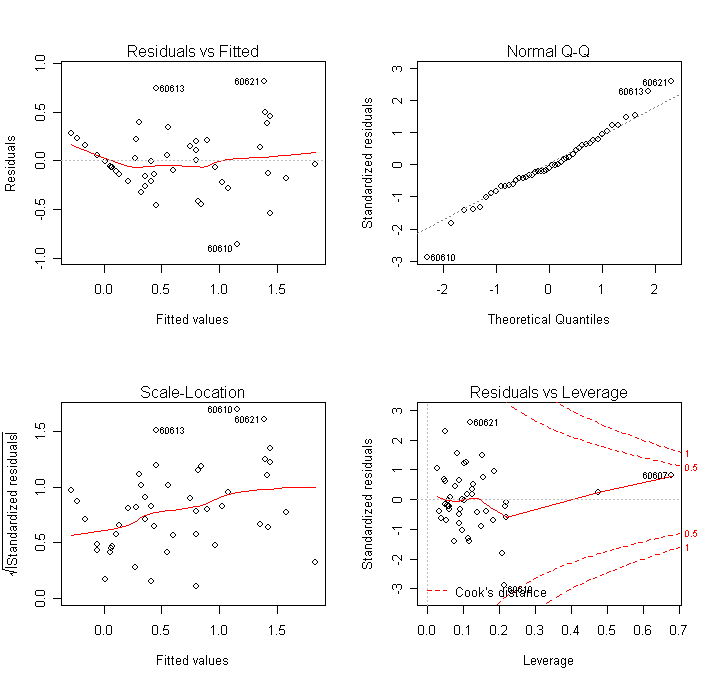
The diagonal streak in the residual-fitted plot is caused by the large number of zero response values in the data. Turning a blind eye to this feature, we see no particular problem. The Q-Q plot looks fine too.
Now, check out the jacknife residuals:
>
jack <- rstudent(g)
> qt(0.05/(2*47), 47-6-1)
[1] -3.529468
> jack[ abs(jack) > 3.529468 ]
[1] -3.529468
Nothing too extreme - now look at the Cook statistics.
> cooks <- cooks.distance(g)
> row.names(chicago)[cooks>0.1]
[1] "60610" "60607" "60653" "60621"
Data with zip codes "60610", "60607", "60653", and "60621" correspond to the four largest influence points.
Now let's look at influence - what happens if points are excluded?
> gi <- lm.influence(g)
>
par(mfrow=c(2,3))
> for(i in 1:5) {plot(gi$coef[,i+1],
main=names(chicago)[-5][i]); abline(h=0); identify(1:47, gi$coef[,i+1],
row.names(chicago))}
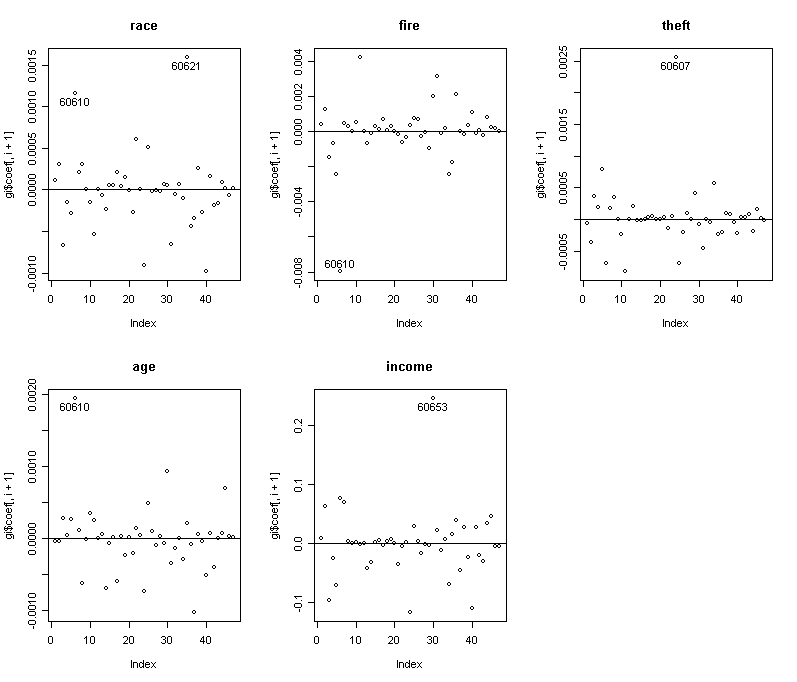
Same points stand up.
> chicago[c("60610", "60607", "60621", "60653") ,]
race fire
theft age involact income
60610 54.0 34.1 68 52.6 0.3 8.231
60607 50.2 39.7 147 83.0 0.9 7.459
60621 98.9 17.4 32 68.6 2.2 7.520
60653 99.7 21.6 31 65.0 0.9 5.583
Roughly speaking, "60610" and "60607" have high theft and fire, "60621" and "60653" have high race and low income.
See what happens when we exclude these points:
> summary(lm(involact ~ race + fire + theft + age + log(income), subset=(cooks < 0.3), data = chicago))
Call:
lm(formula = involact ~ race + fire + theft + age + log(income),
data = chicago, subset = (cooks < 0.3))
Residuals:
Min 1Q Median 3Q Max
-0.60023 -0.19909 -0.03575 0.14419 0.81399
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.944335 0.997770 -0.946 0.349604
race 0.008341 0.002280 3.658 0.000734 ***
fire 0.047845 0.008314 5.755 1.05e-06 ***
theft -0.009601 0.002557 -3.754 0.000553 ***
age 0.006386 0.002556 2.499 0.016666 *
log(income) 0.268647 0.362616 0.741 0.463106
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3025 on 40 degrees of freedom
Multiple R-Squared: 0.8008, Adjusted R-squared: 0.776
F-statistic: 32.17 on 5 and 40 DF, p-value: 5.176e-13
> summary(lm(involact ~ race + fire + theft + age + log(income), subset=(cooks < 0.2), data = chicago))
Call:
lm(formula = involact ~ race + fire + theft + age + log(income),
data = chicago, subset = (cooks < 0.2))
Residuals:
Min 1Q Median 3Q Max
-0.63445 -0.21208 -0.02757 0.15580 0.83307
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.576737 1.080046 -0.534 0.5964
race 0.007053 0.002696 2.616 0.0126 *
fire 0.049647 0.008570 5.793 1.00e-06 ***
theft -0.006434 0.004349 -1.479 0.1471
age 0.005171 0.002895 1.786 0.0818 .
log(income) 0.115703 0.401113 0.288 0.7745
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3032 on 39 degrees of freedom
Multiple R-Squared: 0.8041, Adjusted R-squared: 0.779
F-statistic: 32.01 on 5 and 39 DF, p-value: 8.192e-13
> summary(lm(involact ~ race + fire + theft + age + log(income), subset=(cooks < 0.1), data = chicago))
Call:
lm(formula = involact ~ race + fire + theft + age + log(income),
data = chicago, subset = (cooks < 0.1))
Residuals:
Min 1Q Median 3Q Max
-0.39639 -0.16735 -0.01644 0.15024 0.66508
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.390509 0.970290 0.402 0.6897
race 0.004722 0.002342 2.016 0.0511 .
fire 0.050627 0.007259 6.974 3.07e-08 ***
theft -0.004373 0.003697 -1.183 0.2443
age 0.003247 0.002509 1.294 0.2036
log(income) -0.244163 0.360638 -0.677 0.5026
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2551 on 37 degrees of freedom
Multiple R-Squared: 0.8459, Adjusted R-squared: 0.825
F-statistic: 40.61 on 5 and 37 DF, p-value: 4.933e-14
I decide to exclude only the first two zip codes with largest cook's distance, i.e., "60610" and "60607".
> g <- lm(involact ~ race + fire + theft + age + log(income), subset=(cooks < 0.2), data = chicago)
> summary(g)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.576737 1.080046 -0.534 0.5964
race
0.007053 0.002696 2.616 0.0126 *
fire
0.049647 0.008570 5.793 1.00e-06 ***
theft
-0.006434
0.004349 -1.479 0.1471
age
0.005171 0.002895 1.786 0.0818 .
log(income) 0.115703 0.401113 0.288 0.7745
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1
` ' 1
Residual standard error: 0.3032
on 39 degrees of freedom
Multiple R-Squared:
0.8041, Adjusted
R-squared: 0.779
F-statistic: 32.01 on 5 and 39 DF, p-value: 8.192e-13
After they are excluded, theft and age are no longer significant at the 5% level. We now address the question of transformations - because the response has some zero values and for interpretational reasons we will not try to transform it. Similarly, since the race variable is the primary predictor of interest we won't try transforming it either so as to avoid interpretation difficulties. We try fitting a polynomial model with quadratic terms in each of the predictors:
>
g2 <- lm(involact ~ race + poly(fire,2) + poly(theft,2) + poly(age,2) +
poly(log(income),2), subset=(cooks <0.2), data = chicago)
>
anova(g,g2)
Analysis of Variance Table
Model 1: involact ~ race + fire
+ theft + age + log(income)
Model 2: involact ~ race +
poly(fire, 2) + poly(theft, 2) + poly(age,
2) + poly(log(income),
2)
Res.Df RSS Df Sum of Sq F Pr(>F)
1 39 3.5853
2 35 3.2037 4 0.3816 1.0424 0.3994
It seems that we can do without the quadratic terms. A check of the partial residual plots also reveals no need to transform. We now move on to variable selection. We are not so much interested in picking one model here because we are mostly interested in the dependency of involact on the race variable. So brace is the thing we want to focus on. The problem is that collinearity with the other variables may cause brace to vary substantially depending on what other variables are in the model. We address this question here. leaps() is bit picky about its input format so I need to form the X and Y explicitly:
>
y <- chicago$involact[cooks < 0.2]
> x <- cbind(chicago[cooks
< 0.2,1:4], linc=log(chicago[cooks < 0.2,6]))
> library(leaps)
> a <-
leaps(x,y)
Now, make the Cp plot:
>
par(mfrow=c(1,1))
> plot(a$size, a$Cp, xlab="p", ylab="Cp");
abline(0,1)
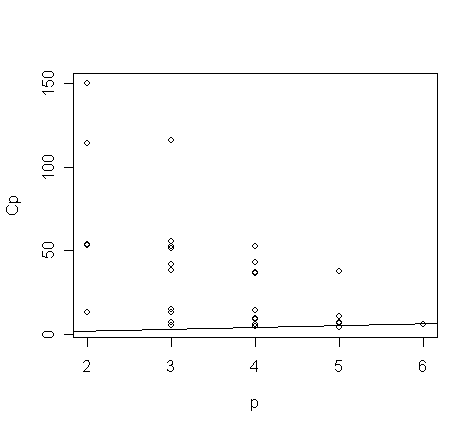
> small <- (a$Cp < 10)
> plot(a$size[small], a$Cp[small], xlab="p", ylab="Cp"); abline(0,1)
> a.labels <- apply(a$which,1,function(x) paste(as.character((1:5)[x]),collapse=""))
> text(a$size[small], a$Cp[small], a.labels[small], cex=0.8)
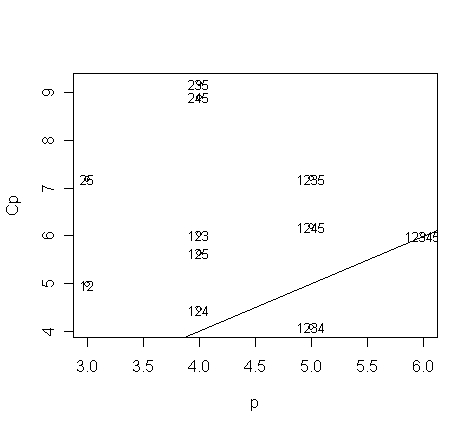
Now, the best model seems to be this one:
>
g <- lm(involact ~ race + fire + theft + age, data=chicago, subset=(cooks
< 0.2))
> summary(g)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.267870 0.139668 -1.918 0.06228 .
race
0.006489 0.001837 3.532 0.00105 **
fire
0.049057 0.008226 5.963 5.32e-07 ***
theft
-0.005809
0.003728 -1.558 0.12709
age
0.004688 0.002334 2.009 0.05136 .
---
Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1
` ' 1
Residual standard error: 0.2997
on 40 degrees of freedom
Multiple R-Squared:
0.8037, Adjusted
R-squared: 0.784
F-statistic: 40.93 on 4 and 40 DF, p-value: 1.238e-13
Now fit all the contenders and check out the coefficient for race - you will find it is significant in all of them. The fire rate is also significant and actually has higher t-statistics. Thus, we have verified that there is a positive relationship between involact and race while controlling for a selection of the other variables. This gives us some confidence in asserting that there is a strong relationship that is not sensitive to the choice of predictors.
How robust is the conclusion? Would other analysts have come to the same conclusion? One alternative model is:
> galt <- lm(involact~ race + fire + log(income), data=chicago, subset=(cooks < 0.2))
> summary(galt)
Call:
lm(formula = involact ~ race + fire + log(income), data = chicago,
subset = (cooks < 0.2))
Residuals:
Min 1Q Median 3Q Max
-0.751476 -0.192795 -0.006213 0.110723 0.874113
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.753256 0.835880 0.901 0.3728
race 0.004206 0.002276 1.848 0.0718 .
fire 0.051022 0.008450 6.038 3.82e-07 ***
log(income) -0.362382 0.319162 -1.135 0.2628
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3092 on 41 degrees of freedom
Multiple R-Squared: 0.7858, Adjusted R-squared: 0.7701
F-statistic: 50.14 on 3 and 41 DF, p-value: 8.873e-14
In this model, we see that race is not statistically significant. The previous model did fit slightly better but it is important that there exists a reasonable model in which race is not significant since although the evidence seems fairly strong in favor of a race effect, it is not entirely conclusive. Interestingly enough, if log(income) is dropped:
> galt <- lm(involact~ race + fire, data=chicago, subset=(cooks < 0.2))
> summary(galt)
Call:
lm(formula = involact ~ race + fire, data = chicago, subset = (cooks <
0.2))
Residuals:
Min 1Q Median 3Q Max
-0.65891 -0.20471 -0.01654 0.13807 0.87525
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.191325 0.081517 -2.347 0.02371 *
race 0.005712 0.001856 3.078 0.00366 **
fire 0.054664 0.007845 6.968 1.61e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3103 on 42 degrees of freedom
Multiple R-Squared: 0.7791, Adjusted R-squared: 0.7686
F-statistic: 74.05 on 2 and 42 DF, p-value: 1.696e-14
We find race again becomes significant which raises again the question of whether income should be adjusted for since it makes all the difference here. It's recommended to study the collinearity structure in the predictor to gain more understanding about why it happens.
We now return to the two left-out cases. Observe the difference in the fit when the two are re-included on the best model. The quantities may change but the qualitative message is the same. It is better to include all points if possible, especially in a legal case like this where excluding points might lead to criticism and suspicion of the results.
>
g <- lm(involact ~ race + fire + theft + age, data=chicago)
>
summary(g)
Call:
lm(formula = involact ~ race + fire + theft + age, data = chicago)
Residuals:
Min 1Q Median 3Q Max
-0.87108 -0.14830 -0.01961 0.19968 0.81638
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.243118 0.145054 -1.676 0.101158
race 0.008104 0.001886 4.297 0.000100 ***
fire 0.036646 0.007916 4.629 3.51e-05 ***
theft -0.009592 0.002690 -3.566 0.000921 ***
age 0.007210 0.002408 2.994 0.004595 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3335 on 42 degrees of freedom
Multiple R-Squared: 0.7472, Adjusted R-squared: 0.7231
F-statistic: 31.03 on 4 and 42 DF, p-value: 4.799e-12
The main message of the data is not changed - better check the diagnostics:
> par(mfrow=c(2,2)); plot(g)
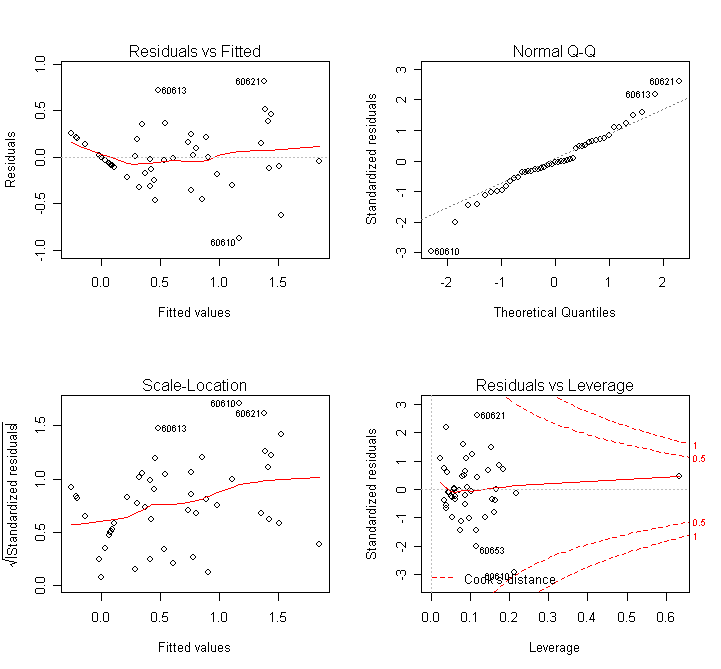
which indicates no trouble. (adding back in the two points to the race+fire+log(income) model made race significant again.) So, it looks like there is some good evidence that zip codes with high minority populations are being "redlined'' - that is improperly denied insurance. While there is evidence that some of the relationship between race and involact can be explained by the fire rate, there is still a component that cannot be attributed to the other variables. However, note that there is some doubt due to the response not being a perfect measure of people being denied insurance - it only appears to be a good substitute. I would guess the effect would be stronger if we did get to see the true response but there is no way to show that with the evidence available. There is also the problem of a potential latent variable that might be the true cause of the observed relationship, but it is difficult to see what that variable might be.
There are some special difficulties in presenting this during a court case. With scientific enquiries, there is always room for uncertainty and subtlety in presenting the results, but this is much more difficult in the court room. The jury may know no statistics and lawyers are clever at twisting words. A statistician giving evidence as an expert witness would do well to keep the message simple.