Poisson Regression (Reading: Faraway (2006), section 3.1)
Here is a data which
recorded the counts of the numbers of species of tortoise found on 30 Galapagos
Islands and the numbers that are endemic to that island. The data also contains
five geographic variables for each island. The data was presented by Johnson and
Raven (1973). A few missing values that appeared in the original dataset have
been filled for simplicity.
We start the analysis of the data by reading the data into R and throw out the
Endemics variable (which falls in the 2nd column of the data frame) since we
won't be using it in this analysis.
> gala <- read.table("gala.txt")
> gala
Species Endemics Area Elevation Nearest Scruz Adjacent
Baltra 58 23 25.09 346 0.6 0.6 1.84
Bartolome 31 21 1.24 109 0.6 26.3 572.33
Caldwell 3 3 0.21 114 2.8 58.7 0.78
…deleted…
Wolf 21 12 2.85 253 34.1 254.7 2.33
> gala <- gala[,-2]
Let us first fit a Normal linear model:
> modl <-
lm(Species ~ . , gala)
> summary(modl)
Call:
lm(formula = Species ~ ., data = gala)
Residuals:
Min 1Q Median 3Q Max
-111.679 -34.898 -7.862 33.460 182.584
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.068221 19.154198 0.369 0.715351
Area -0.023938 0.022422 -1.068 0.296318
Elevation 0.319465 0.053663 5.953 3.82e-06 ***
Nearest 0.009144 1.054136 0.009 0.993151
Scruz -0.240524 0.215402 -1.117 0.275208
Adjacent -0.074805 0.017700 -4.226 0.000297 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 60.98 on 24 degrees of freedom
Multiple R-Squared: 0.7658, Adjusted R-squared: 0.7171
F-statistic: 15.7 on 5 and 24 DF, p-value: 6.838e-07
We find that:
the fit has a fairly good R2, 76.58%, which seems suggest this is a good fit.
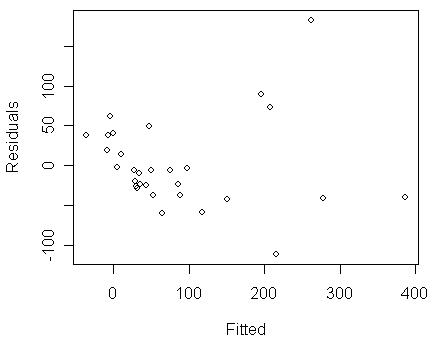
however, let us take a look at a diagnostic plot of residuals versus fitted values:
> plot(predict(modl),residuals(modl),xlab="Fitted",ylab="Residuals")
Notice that:
in the figure, we can see clear evidence of non-constant variance (i.e., Var(yx) becomes larger when E(yx) increases)
Q: for the distributions we have ever seen in the lectures, which one has the property that its variance increases with its mean?
Q: why all points lie above a downward sloping line on the left side of the figure? It happens because
the values of the response ³ a constant c, which is 0 in this case, and
many values of the response » c (which can be found from the stem plot below)
Because of 1., residual = y-(fitted y) ³ c-(fitted y). Because of 2., many residuals » c-(fitted y), which accounts for the line forming a lower bound on the scatter plot of residual versus fitted y.
> stem(gala$Spec)
The decimal point is 2 digit(s) to the right of the |
0 | 0000111122223344
0 | 566679
1 | 001
1 |
2 | 4
2 | 89
3 |
3 | 5
4 | 4
if we persist in the Normal linear model approach, a possible remedy is to transform the response. Some experimentation (such as the use of the Box-Cox transformation method) suggests that a square-root transformation is best
Let us follow the suggestion to fit a model by using the square-root of Species as the response and draw the same residual plot for the new model:
> modt <- lm(sqrt(Species) ~ . , gala)
> plot(predict(modt),residuals(modt),xlab="Fitted",ylab="Residuals")
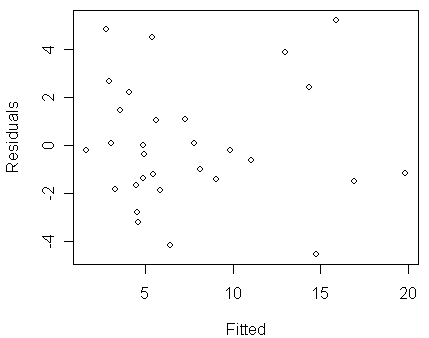
We now see that the non-constant variance problem have been cleared up in the new model. Let us take a look at the fit:
> summary(modt)
Call:
lm(formula = sqrt(Species) ~ ., data = gala)
Residuals:
Min 1Q Median 3Q Max
-4.5572 -1.4969 -0.3031 1.3527 5.2110
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.3919243 0.8712678 3.893 0.000690 ***
Area -0.0019718 0.0010199 -1.933 0.065080 .
Elevation 0.0164784 0.0024410 6.751 5.55e-07 ***
Nearest 0.0249326 0.0479495 0.520 0.607844
Scruz -0.0134826 0.0097980 -1.376 0.181509
Adjacent -0.0033669 0.0008051 -4.182 0.000333 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.774 on 24 degrees of freedom
Multiple R-Squared: 0.7827, Adjusted R-squared: 0.7374
F-statistic: 17.29 on 5 and 24 DF, p-value: 2.874e-07
Notice that:
we see a fairly good fit (R2=0.7827) considering the nature of the variables
however, we achieved this fit at the cost of transforming the response
the transformation makes interpretation more difficult because the estimated parameters need to be interpreted with respect to the scale of square-root of count
for this data, some of the response values are quite small and close to the lower bound of count (i.e., 0), which makes us question the validity of the a Normal linear model
For count responses as in this case, we can model the response by using Poisson
distribution. Notice that the variance of Poisson increases with its mean. We
now fit a Poisson GLM to the Galapagos data:
> modp <- glm(Species ~ .,family=poisson,gala)
> summary(modp)
Call:
glm(formula = Species ~ ., family = poisson, data = gala)
Deviance Residuals:
Min 1Q Median 3Q Max
-8.2752 -4.4966 -0.9443 1.9168 10.1849
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.155e+00 5.175e-02 60.963 < 2e-16 ***
Area -5.799e-04 2.627e-05 -22.074 < 2e-16 ***
Elevation 3.541e-03 8.741e-05 40.507 < 2e-16 ***
Nearest 8.826e-03 1.821e-03 4.846 1.26e-06 ***
Scruz -5.709e-03 6.256e-04 -9.126 < 2e-16 ***
Adjacent -6.630e-04 2.933e-05 -22.608 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 3510.73 on 29 degrees of freedom
Residual deviance: 716.85 on 24 degrees of freedom
AIC: 889.68
Number of Fisher Scoring iterations: 5
The format of the output is same as that for binomial GLM because they are members of generalized linear models. We can find from the output that:
the residual deviance is 716.85 on 24 degrees of freedom, which indicates an ill-fitting model if the Poisson is the correct model for the response (i.e., the null hypothesis). Some explanations for the large deviance are:
outlier
wrong Xb structure
over-dispersion
We will examine the validity of these explanations in the following analysis.
exercise: compare the results of this Poisson GLM fit and the Normal linear model fits. Check what information in the two results are similar, what are different. Explain why Nearest, and Scruz are so significant in the Poisson fit, but insignificant in the Normal fits. What could possibly cause it?
Using the function written by Prof. Faraway, we can draw a half-normal plot for the residuals to see whether the large deviance can be explained by an outlier:
> halfnorm(residuals(modp))
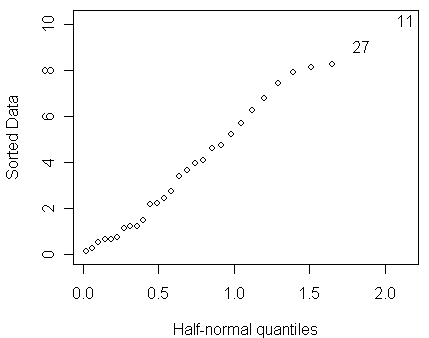
We do not see any clear evidence of outlier in the half-normal plot.
It could be the Xb structure form of the model needs some improvement, but some experimentation with different form for the predictors will reveal that :
there is little scope for improvement (exercise: perform different Xb structures to confirm it by yourself)
furthermore, the proportion of deviance explained by this model, i.e., 1-716.85/3510.73=0.7958117, is about the same as the R2 in the Normal linear model above
Let us now go to the last explanation --- over-dispersion. For a Poisson distribution, the mean is equal to the variance. Let us investigate this relationship for this model. It is difficult to estimated the variance for a given value of the mean, but (yx-(mx-hat))2 does serve as a crude approximation. We plot this estimated variance against the mean:
>
plot(log(fitted(modp)),log((gala$Species-fitted(modp))^2),xlab=expression(hat(mu)),ylab=expression((y-hat(mu))^2))
> abline(0,1)
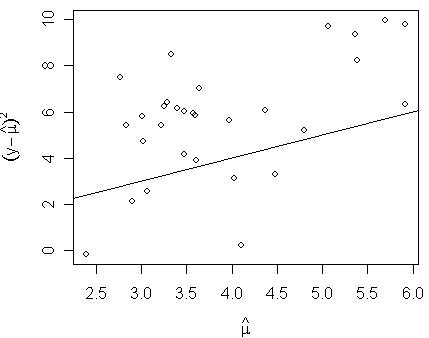
We see that the variance is proportional to, but larger than, the mean.
For the cases of over-dispersion, we can generalize the Poisson GLM by allowing a dispersion parameter s2 such that:
Var(yx)=s2E(yx).
The dispersion parameter can be estimated by:
> (dp <- sum(residuals(modp,type="pearson")^2)/modp$df.res)
[1] 31.74914
We can then adjust the standard errors of b-hat and so forth in the summary as follow:
> summary(modp,dispersion=dp)
Call:
glm(formula = Species ~ ., family = poisson, data = gala)
Deviance Residuals:
Min 1Q Median 3Q Max
-8.2752 -4.4966 -0.9443 1.9168 10.1849
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.1548079 0.2915897 10.819 < 2e-16 ***
Area -0.0005799 0.0001480 -3.918 8.95e-05 ***
Elevation 0.0035406 0.0004925 7.189 6.53e-13 ***
Nearest 0.0088256 0.0102621 0.860 0.390
Scruz -0.0057094 0.0035251 -1.620 0.105
Adjacent -0.0006630 0.0001653 -4.012 6.01e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 31.74914)
Null deviance: 3510.73 on 29 degrees of freedom
Residual deviance: 716.85 on 24 degrees of freedom
AIC: 889.68
Number of Fisher Scoring iterations: 5
Notice that:
the estimation of the dispersion parameter s2 and the regression parameter b are independent, so choosing a dispersion other than one has no effect on the regression parameter estimation (exercise: check whether the two Poisson fits, with and without dispersion parameter, have same estimates of b)
but, the standard errors and z-statistics are changed
exercise: compare this result with the Normal linear model fits. Examine what information in the results are similar, what are different. (Notice that Nearest and Scruz become insignificant in the Poisson fit with dispersion parameter, which is consistent with what we observed in the Normal fits.)
To compare two nested models, we now need to use F-test, rather than chi-square test:
> drop1(modp,test="F")
Single term deletions
Model:
Species ~ Area + Elevation + Nearest + Scruz + Adjacent
Df Deviance AIC F value Pr(F)
<none> 716.85 889.68
Area 1 1204.35 1375.18 16.3217 0.0004762 ***
Elevation 1 2389.57 2560.40 56.0028 1.007e-07 ***
Nearest 1 739.41 910.24 0.7555 0.3933572
Scruz 1 813.62 984.45 3.2400 0.0844448 .
Adjacent 1 1341.45 1512.29 20.9119 0.0001230 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Warning message:
F test assumes 'quasipoisson' family in: drop1.glm(modp, test = "F")
The F-test is more reliable than the z-statistics although it makes little difference for this data.